
목록전체 글 (150)
Just Fighting
 RNN을 이용한 텍스트 생성 연습
RNN을 이용한 텍스트 생성 연습
https://wikidocs.net/45101 위의 사이트를 보고 RNN을 이용한 텍스트 생성을 연습해보았다. 전체적인 과정은 이렇다. 먼저 여러 문장들을 단어별로 나누고 문장을 앞에서부터 잘라 여러 배열을 만들고 모델 학습을 통해 단어 혹은 문장 뒤에 올 새로운 단어를 예측하는 것이다. 먼저 라이브러리부터 임포트! import numpy as np from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences from tensorflow.keras.utils import to_categorical from tensorflow.keras.mode..
 [SAS] if-else 문 사용하기
[SAS] if-else 문 사용하기
if-else문은 아래 사진과 같이 사용하면 된다. if 조건 then 결과 else if 조건 then 결과 "길이를 안정해줘서 맨 첫번째꺼의 길이로 설정됨"의 의미는 SALRANGE의 길이가 정해지지 않았기 때문에 맨 처번째 결과인 "LOW"의 길이를 따라간다. 그래서 아래 표에 모든 값이 3글자인 것이다. length문을 사용해 길이를 정해줄 수 있다. 길이를 9로 하니까 글자가 잘리지 않고 다 나오는 것을 볼 수 있다. 또한 문자같은 경우에 작은 따옴표나 큰따옴표 모두 사용가능하다. 앞선 게시글과 이어지는 내용이라고 할 수 있다. 2022.03.31 - [Statistics/SAS] - [SAS] 새로운 변수 생성하기 아래처럼 mean함수와 if-else문을 같이 사용하는 것도 가능하다. if문의..
 [PySpark] 하이퍼 파라미터 튜닝하기
[PySpark] 하이퍼 파라미터 튜닝하기
2022.03.29 - [ETC] - [PySpark] Pipeline 사용하기 이전 게시글에 이어서 모델을 튜닝해보고자 한다. 모델 튜닝을 위해서 ParamGridBuilder와 CrossValidator를 사용한다. ParamGridBuilder를 통해 조절하고 싶은 변수들의 값들을 지정해준다. 그리고 CrossValidator를 이용해 각 경우의 수에 따라 모델을 생성한다. # 모델 튜닝 from pyspark.ml.tuning import ParamGridBuilder, CrossValidator paramGrid = (ParamGridBuilder() .addGrid(lr.maxIter, [100, 120]) .addGrid(lr.regParam, [0.0, 0.1]) .addGrid(lr.el..
 [SAS] 새로운 변수 생성하기
[SAS] 새로운 변수 생성하기
기존 변수로 새로운 변수를 생성할 수 있다. 아래 사진과 같이 input문에 작성하면 된다. 이때 max같은 경우에는 retain문과 함께 작성해주어야 한다. 바로 위에 행의 max값을 갖고있겠다는 의미가 되어 맨 마지막 행의 값이 가장 큰 값이 된다. 결측값이 있을 경우는 아래 사진과 같다. mean() 함수를 사용했을 때는 결측값을 제외하고 평균을 구하지만 더해서 2로 나누어 평균을 구할 때는 결측값 때문에 계산이 되지 않는 것을 볼 수 있다. 누적된 값을 구하고 싶을 때는 아래 사진처럼 작성하면 된다.
 [PySpark] Pipeline 사용하기
[PySpark] Pipeline 사용하기
파이프라인은 여러 기계 학습 알고리즘을 함께 결합하는 완전한 워크플로이다. 데이터를 처리하고 학습하는데 필요한 여러 단계와 순서를 정의한다. 내가 이해한 바로는 모델을 만드는데 필요한 단계를 따로따로 수행하는 것이 아니라 그것을 하나의 과정으로 만들어 더욱 쉽게 수행할 수 있게 도와주는 것 같다. 2022.03.24 - [ETC] - [PySpark] MLlib를 이용한 로지스틱 회귀분석 로지스틱 회귀분석의 과정을 Pipeline을 사용하여 더욱 편리하게 하고자 한다. VectorAssembler과정과 LogisticRegression과정을 진행한다. 이전 게시글에선 이 과정을 따로 수행했다. 하지만 이번에는 Pipeline을 이용해여 한 번에 수행할 수 있었다. # 독립변수 묶기 from pyspark..
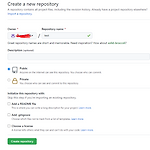 [Git] 로컬 저장소 GitHub에 연동 & 커밋하기
[Git] 로컬 저장소 GitHub에 연동 & 커밋하기
내 컴퓨터에 차곡차곡 쌓여있는 프로젝트 파일을 깃허브에 올리기 위해 열심히 공부했다,,ㅎㅎ Git을 먼저 다운받아야함!!!! 먼저 repository를 하나 생성한다. 생성하면 두번째 사진과 같이 화면이 뜬다. 이때 create a new repository on th command line에 있는 코드를 이용하면 된다. 대신 살짝만 바꾸어서 사용한다. 먼저 내 파일들이 가득 들어있는 폴더를 오른쪽 마우스로 클릭해서 Git Bash Here을 클릭한다. 그럼 아래처럼 git cmd창이 뜬다. 거기에 아래 코드를 한 줄씩 써주면 된다. git init git add . git commit -m "first commit" git branch -M main git remote add origin https:/..
 [프로그래머스] 디스크 컨트롤러
[프로그래머스] 디스크 컨트롤러
https://programmers.co.kr/learn/courses/30/lessons/42627 코딩테스트 연습 - 디스크 컨트롤러 하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다. 디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 요청이 들어온 순서대로 처리하는 것입니다. 예를 programmers.co.kr 간단하게 설명하자면 SJF방식을 이용해 평균 반환시간을 구하면 된다. import heapq def solution(jobs): answer = 0# 작업을 처리하는데 걸린 총 시간 jobs.sort()# 정렬. 맨 처음에 들어온 작업을 찾기 위함. heap = []# 바로 다음에 처리할 수 있는 작업 리스트. 힙큐 st..
 [PySpark] MLlib를 이용한 로지스틱 회귀분석
[PySpark] MLlib를 이용한 로지스틱 회귀분석
1. 데이터 가져오기 먼저 사용할 데이터를 가져온다. (데이터 전처리는 생략) 2022.02.24 - [ETC] - [Spark] pyspark로 hdfs 데이터 불러오기 위의 링크를 이용해 데이터를 가져온다. 2. feature 묶어주기 (독립변수 묶어주기) # 독립변수 묶기 # https://spark.apache.org/docs/latest/ml-features.html#vectorassembler from pyspark.ml.feature import VectorAssembler assembler = VectorAssembler( inputCols=data.columns[1:], outputCol="features") data = assembler.transform(data) 3. test, tr..
 결측값 처리하기 2 (평균, 중앙값)
결측값 처리하기 2 (평균, 중앙값)
이전에 결측값 처리하는 게시물을 작성했던 적이 있다. 그때는 이제 결측값이 있는 행을 지우고, 남은 결측값에 하나의 값을 넣어주었다. 2022.02.13 - [Statistics/Python] - 결측값 처리하기 이번에는 열의 평균값이나 중앙값으로 변경하는 방법에 대해 정리하려고 한다. 먼저 numpy와 pandas 임포트부터! 아래 사진과 같은 데이터를 이용해 결측값을 처리해보는 연습을 했다. import numpy as np import pandas as pd 결측값을 대체하기 전에 먼저 평균과 중앙값을 구하는 코드를 보자. 아래 사진을 보면 평균을 구하는 코드에는 NaN값이 있어도 잘 계산이 되지만 중앙값을 구할 때는 계산이 되지 않는 것을 볼 수 있다. 그때 사용할 수 있는 함수가 nanmedia..
 [프로그래머스] 프린터
[프로그래머스] 프린터
https://programmers.co.kr/learn/courses/30/lessons/42587 코딩테스트 연습 - 프린터 일반적인 프린터는 인쇄 요청이 들어온 순서대로 인쇄합니다. 그렇기 때문에 중요한 문서가 나중에 인쇄될 수 있습니다. 이런 문제를 보완하기 위해 중요도가 높은 문서를 먼저 인쇄하는 프린 programmers.co.kr 인쇄 대기목록에 가장 앞에 있는 문서가 우선순위가 가장 높으면 출력하고 그렇지 않으면 목록의 맨 뒤로 보낸다. 내가 요청한 문서가 몇번째로 출력되는지 알고 싶다. 문서의 중요도를 나타내는 배열이 priorities와 내가 요청한 문서의 위치인 location이 주어진다. 문서의 우선순위와 문서의 번호를 함께 생각해서 문제를 풀면 ..