Transformer, Attention 정리
앞서 논문 리뷰를 했으나, 제대로 이해하지 못한 것 같아서 추가적인 공부를 진행했다.
그런데 이제 ChatGPT와 함께한,,ㅎㅎ

1. 트랜스포머의 목적은?
트랜스포머는 말을 얼마나 잘 만드느냐가 중요한 것이다.
번역에 대한 값은 이미 다 있다. rose가 장미라는 사실을 알고 있다.
'rose is flower'라는 말을 번역하기 위해 '장미', '는', '꽃', '이다'를 어떻게 배열할 것인지에 대한 문제.
잘 배열하기 위해서 단어 간의 관계를 학습하는 것이다.
단어 간의 관계를 학습하기 위해 어텐션을 사용하는 것이고,
하나에서 답을 얻는 것보단 여러 개에서 답을 얻어 사용하는 것이 좋으니까 멀티헤드 어텐션을 사용하는 것.
2. 어텐션의 쿼리, 키, 밸류의 행렬은 어떻게 계산하는가?
입력값을 임베딩하고, 쿼리 가중치, 키 가중치, 밸류 가중지를 내적한 것이다.
각각의 가중치는 하나씩 존재하며($W^Q, W^K, W^V$), 각 단어마다 Q, K, V 벡터가 생성되는 것.
행렬을 이용하면 한 번에 계산 가능!

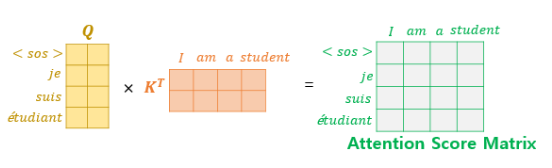
Attention Score의 계산과정은 다음과 같다.
쿼리와 키를 내적해서 $d_k$(쿼리와 키의 차원)로 스케일링을 진행한다.
그 결과로 나온 값이 Attention score이며, 단어와의 연관성에 대한 점수다.
어텐션 값을 구하는 식을 그림으로 표현하면 다음과 같다.
$ Attention(Q, K, V) = softmax(\dfrac{QK^T}{\sqrt {d_k}})V $

가중치는 학습 시 업데이트가 되는 것.
2-1. 멀티헤드 어텐션의 최종 값은 어떻게 계산하는가?
병렬로 진행한 어텐션의 결과를 연결한다.
각각의 헤드의 결과는 $(seq\_len, d_{model}/h)$ 이며,
멀티헤드 어텐션의 결과는 $(seq\_len, d_{model})$을 가진다.
$d_k = d_v = d_{model}/h = 64$

3. 각각 어텐션은 무엇을 학습하는 것인가?

- 인코더의 self-attention
입력 시퀀스 내의 각 토큰과의 관계를 학습한다.
예) "The cat sat on the mat because it was tired.” → lt 는 cat
- 디코더의 self-attention
시퀀스 내의 각 토근과의 관계를 학습하는 건 똑같은데,
어텐션 점수$\dfrac{QK^T}{\sqrt {d_k}}$의 $QK^T$를 마스킹하는 것임.
어텐션 점수는 유사도 점수고, 정보의 유출을 막기 위해 $-\infty$ 로 값 변경
- encoder-decoder attention 인코더-디코더 어텐션
인코더의 출력과 디코더의 입력간의 관계를 학습
"The cat is sleeping" → "Le chat dort” : "cat"이 "chat"에 대응됨을 학습.
4. 트랜스포머 구조의 인코더, 디코더 각각의 입력값, 출력값은 무엇인가?
<인코더>
- 입력 : 입력문장 토큰 임베딩 + 포지셔널 임베딩
- 출력 : 모든 단어에 대한 컨텍스트 벡터
- 컨텍스트 벡터 : 단어의 벡터가 다른 단어와의 관계로 인해 변형된 값으로 이뤄진 벡터
<디코더>
- 입력 : 시퀀스의 이전 단어들, 인코더의 출력(컨텍스트 벡터)
- 학습 시에는 정답값을 넣고, 실제 사용 시에는 앞서나온 결과를 넣는다.
- 학습 시에는 teacher forcing과 look-ahead mask를 사용(병렬연산)
- 출력 : 다음 토큰을 예측하는 확률 분포
- 소프트 맥스 함수를 이용해 최종 단어 선택
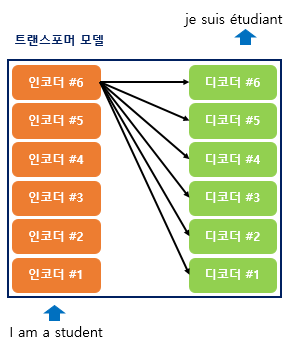
4-1. n개의 인코더, 디코더의 연산은 어떻게 진행되는 것인가?
인코더의 입력값이 인코더 1에 들어가고, 인코더1의 결과가 인코더 2로, 인코더 2의 결과가 3으로 해서
n개의 인코더를 거쳐 인코더들의 결과를 낸다.
그렇게 나온 인코더의 출력값은 아래 그림처럼 모든 디코더의 인풋에 사용된다.
디코더도 인코더와 비슷하다.
디코더의 입력값과 인코더의 출력값이 디코더 1에 들어가고,
디코더 1의 출력값과 인코더의 출력값이 디코더 2에 들어간다.
그렇게 모든 디코더를 거쳐 결과를 만들어내는 방식이다.
내가 쉽게 이해하려고 간단한 코드를 만들어봤다.
큰 골격만 이용했기 때문에 자세한 코드는 아래 링크 참고
def encoder(inputs):
# 인풋 처리(임베딩, 포지셔널 인코딩, 드롭아웃)
outputs = initialize(inputs)
# 인코더 쌓기
for i in range(n): # n은 인코더 개수
outputs = make_encoder_layer(outputs) # 인코더 층 생성
return outputs
def decoder(inputs, enc_outputs):
# 인풋 처리(임베딩, 포지셔널 인코딩, 드롭아웃)
outputs = intialize(inputs)
for i in range(n):
outputs = make_decoder_layer(outputs, enc_outputs) # 디코더 층 생성
return outputs
# 인코더의 입력
inputs = tf.keras.Input(shape=(None,), name="inputs")
# 디코더의 입력
dec_inputs = tf.keras.Input(shape=(None,), name="dec_inputs")
# encoders, decoders 입출력
enc_outputs = encoder(inputs)
dec_outputs = decoder(dec_inputs, enc_outputs)
5. Feed Forward는 왜 사용하는 것인가?
Feed Forward는 입력값이 출력까지 한 방향으로 전달되는 구조를 가진 인공신경망이다.
multi head attention의 경우 입력된 정보 간의 선형관계만을 모델링 한다.
내적연산이 바로 직선적인 관계 모델링이라고 할 수 있음.
그렇기 때문에 복잡한 패턴이나 비선형 관계를 모델링하는데 어려움.
Feed Forward는 입력층, 은닉층, 출력층을 가지고 있으며,
은닉층에서 비선형 활성화함수를 사용하기 때문에 비선형성을 추가할 수 있다.

[참고]