[논문] Attention Is All You Need (2017) - 1
< Abstract >
'Transformer(트랜스포머)'라고 하는 간단한 네트워크 아키텍처를 새롭게 제안
반복과 컨볼루션을 완전히 없애고, 어텐션 매커니즘을 기반으로 하는 아키텍쳐
=> 보다 병렬적. 학습하는 데 상당히 적은 시간 소요. 질적으로 우수함.
1. Introduction
RNN, LSTM, GRN은 언어 모델링이나 기계학습과 같은 시퀀스 모델링이나 번역에 사용하는 최신 기술.
이런 접근은 순환 언어 모델과 인코더-디코더 아키텍처의 경계를 계속 넓히는 중
- Recurrent Model 순환 모델
입력과 출력의 시퀀스의 *심볼 위치에 따라 계산 진행
이전 은닉상태 $h_{t-1}$과 $t$시점의 입력의 함수로 $h_t$의 시퀀스를 생성
*심볼 : 처리되는 데이터의 기본 단위. 문자, 단어 등
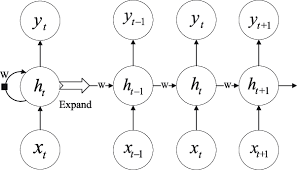
그러나, 순환적인 성질은 병렬화를 어렵게 하며,
시퀀스의 길이가 길어지면 메모리 제약으로 인해 배치작업이 어려워짐
최근엔 인수분해 기법과 조건부 계산을 이용해 계산 효율을 높혔고, 조건부 계산은 모델 성능까지 발전시킴
그래도 근본적인 문제인 순차적인 계산은 여전히 남아있다.
- Attention mechanism(어텐션 메커니즘)
어텐션 메커니즘은 입력 또는 출력 시퀀스의 거리에 상관없는 의존성 모델링 허용
=> 입력 또는 출력시퀀스의 거리가 멀어도 요소 간의 연결되어 있는 관계를 학습할 수 있다는 것을 의미
즉, 어텐션 메커니즘은 순환을 피하면서, 입력과 출력의 전역적인 의존성을 이끌어내는 메커니즘
이 논문에서는 이 어텐션에 완전히 의존하는 모델 아키텍쳐인 트랜스포머를 제안한다.
2. Background
순차적인 연산을 줄이려는 목표를 가진다.
임의의 입력과 출력의 위치로부터 오는 신호를 연결하기 위해서 필요한 연산의 수는
위치에 거리에 따라 ConvS2S는 선형적, ByteNet은 로그형으로 증가한다.
=> 이는 먼 거리 사이의 의존성을 학습을 더 어렵게 함.
*ByteNet : 딥마인드에서 개발한 CNN모델
*ConvS2S : 페이스북에서 발표한 Convolutional Sequence to Sequence Learning. seq2seq 모델을 CNN을 이용해 만든 모델
*seq2seq : sequence to sequence. 인코더와 디코더로 구성됨. 인코더는 입력 문장을 순차적으로 입력받아 모든 벡터를 압축해 하나의 벡터로 만듦(이 벡터는 컨텍스트 벡터라고 함). 그리고 이를 디코더로 전송. 그러면 디코더가 단어를 번역해 하나씩 순차적으로 출력
트랜스포머의 경우 어텐션 메커니즘을 통해 가중치*를 부여받은 위치를 평균화해
해상도 감소라는 대가를 치르지만, 연산의 수를 상수로 감소시킨다.
*가중치는 뒤에 어텐션 메커니즘에서 설명
- self-attention(infra-attention)
self-attention(infra-attention)은 시퀀스의 표현을 계산하기 위해
하나의 시퀀스 내에 서로 다른 위치를 연결하는 어텐션 메커니즘
(뭘 어떻게 연결하는 건지는 뒤에서..!)
문장 독해, 추상적 요약, 텍스트 함의, 독립적인 문장 표현 학습을 포함해 다양한 작업에 쓰인다.
트랜스포머는 입력과 출력의 표현을 계산하기 위해 sequence-aligned RNNs이나 convolution을 사용하지 않고,
전적으로 self-attention에 의존하는 최초의 변환 모델이다.
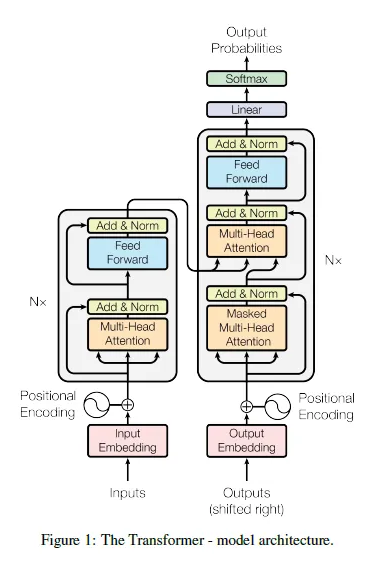
3. Model Architecture
대부분의 신경망 시퀀스 변환 모델은 인코더-디코터 encoder-decoder 구조를 가진다.
- 인코더
심볼의 입력값 시퀀스 $(x_1, x_2, \cdots, x_n)$를 연속적인 표현인 $z=(z_1, z_2, \cdots, z_n)$으로 매핑
- 디코더
$z$가 주어졌을 때, 심볼의 출력값 시퀀스 $(y_1, \cdots, y_n)$을 한 시점에 하나씩 생성
각각의 단계의 모델은
다음을 생성할 때 이전에 생성된 심볼을 추가적인 인풋으로 추정하는 자기 회귀(auto-regressive)이다.
*자기 회귀 모형 : 순차적인 시계열 모형. i번째 시간대의 확률분포 $p(x_i)$를 $i$번째 시간 이전 $< i, (1, 2,\cdots,i-1)$ 까지의 데이터 $x_{<i}, (x_1, x_2, \cdots, x_{i-1})$을 가지고 예측하는 모델. 대표적으로 RNN, Transformer, BERT, GPT 등,,
트랜스포머의 전체적인 구조는 인코더와 디코더가 모두 self-attention과 *point-wise를 쌓아서 만든
완전 연결 계층 fully connected layers의 구조를 따른다.
*point-wise : 각 위치나 요소에 독립적으로 작동하는 연산. 한 번에 하나씩
다음 편에 계속,,