
Just Fighting
[PySpark] Pipeline 사용하기 본문
728x90
파이프라인은 여러 기계 학습 알고리즘을 함께 결합하는 완전한 워크플로이다.
데이터를 처리하고 학습하는데 필요한 여러 단계와 순서를 정의한다.
내가 이해한 바로는 모델을 만드는데 필요한 단계를 따로따로 수행하는 것이 아니라
그것을 하나의 과정으로 만들어 더욱 쉽게 수행할 수 있게 도와주는 것 같다.
2022.03.24 - [ETC] - [PySpark] MLlib를 이용한 로지스틱 회귀분석
로지스틱 회귀분석의 과정을 Pipeline을 사용하여 더욱 편리하게 하고자 한다.
VectorAssembler과정과 LogisticRegression과정을 진행한다.
이전 게시글에선 이 과정을 따로 수행했다.
하지만 이번에는 Pipeline을 이용해여 한 번에 수행할 수 있었다.
# 독립변수 묶기
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(
inputCols=data.columns[1:],
outputCol="features")# 로지스틱 회귀분석
from pyspark.ml.classification import LogisticRegression
lr = LogisticRegression(featuresCol='features', labelCol='win')# 파이프라인
from pyspark.ml import Pipeline
pipeline = Pipeline(stages=[assembler, lr])
model = pipeline.fit(train_data)
예측도 똑같이~~
# 테스트데이터에 대한 예측
pred = model.transform(test_data)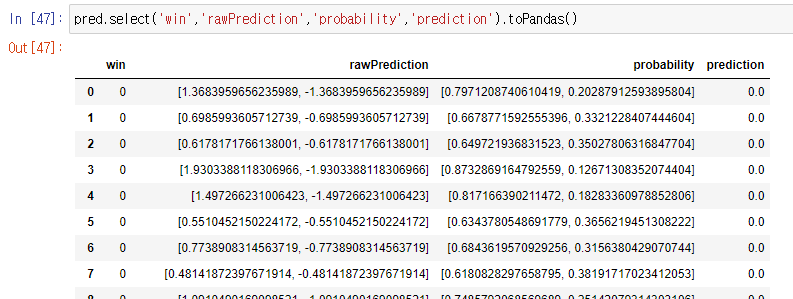
728x90
'Big Data' 카테고리의 다른 글
| [Kafka] 카프카 기본개념 (0) | 2022.05.10 |
|---|---|
| [PySpark] 하이퍼 파라미터 튜닝하기 (0) | 2022.04.02 |
| [PySpark] MLlib를 이용한 로지스틱 회귀분석 (0) | 2022.03.24 |
| [Spark] 데이터 전처리하기(spark sql사용, 결측값 처리) (0) | 2022.03.15 |
| [Spark] pandas dataframe를 hdfs에 저장하기 (0) | 2022.03.12 |
'Big Data' Related Articles
more




Comments