
Just Fighting
[Hadoop] 윈도우에서 하둡 설치 & 실행하기 본문
<참고>
https://codedragon.tistory.com/9582
Hadoop - install for windows (설치 및 설정하기)
Hadoop - install for windows 하둡 설치파일 압축해제 환경변수 추가하기 정상 설치 확인하기 HDFS configurations YARN configurations Initialize environment variables Format file system 설정 Start HDF..
codedragon.tistory.com
위에 블로그를 따라서 하둡을 설치했다.
이전에 다운 받은 spark의 버전에 맞춰 hadoop 3.2.2 를 다운받았다.
2022.02.15 - [ETC] - [Spark] pyspark 설치 & 실행하기
spark를 다운받으면서 같이 다운 받았던 winutils.exe 파일을 하둡파일 안에 있는 bin 폴더로 옮겨주었다.
그리고 추가적으로 hadoop.dll 파일을 다운받아서 넣어주었다.
이것을 넣어준 이유는 하둡을 실행하는 중간에 start-dfs.cmd를 실행할때 namenode 창에서
'ERROR namenode.NameNode: Failed to start namenode. '라는 오류가 나서
구글링했더니 다운받아야 한다고 해서 다운받아서 같이 넣어주었다.
winutils.exe 파일 다운받을 때 옆에 같이 있으니 같이 다운받으면 된다.
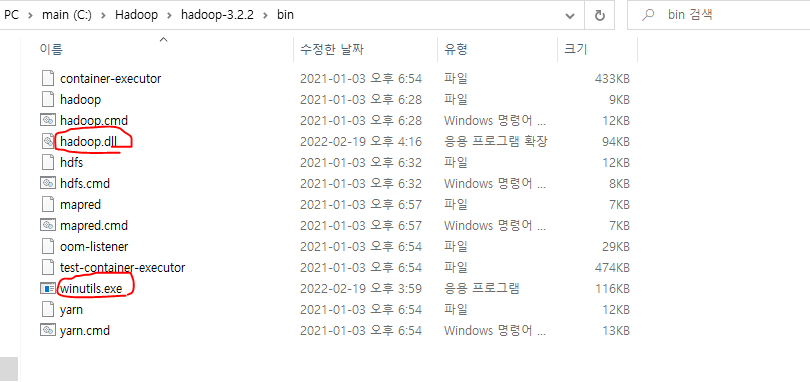
처음에 아무것도 모르고 하둡 여러번 실행해보다가 아래 코드를 여러번 실행했다가
오류가 난적이 있다. 구글링 했더니 namenode와 datanode의 값이 달라져서 그렇다고 한다.
그럴때는 아래 사진의 datanode와 namenode에 있는 파일들을 삭제하고 다시 돌리면 된다.
hadoop namenode -format
주소창에 localhost:8088를 치고 들어갔을 때 아래와 같이 뜨면 잘 된것이다.
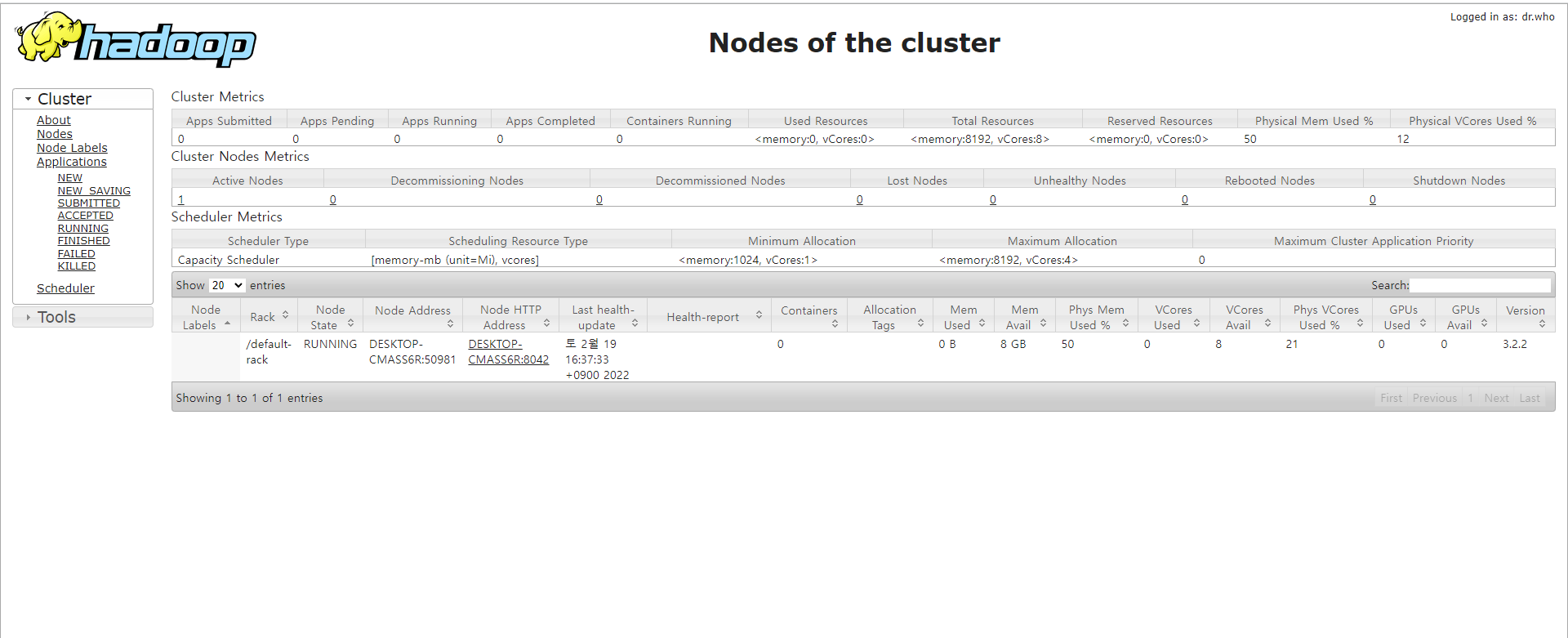
< 실행하기 >
먼저 하둡파일 밑에 sbin 폴더로 이동한다. 나는 c드라이브에 Hadoop이라는 파일을 만들고
그 안에 hadoop 파일을 다운받아서 경로가 이렇다. 각자의 경로에 맞게 바꾸면 된다.
cd C:\Hadoop\hadoop-3.2.2\sbin위치를 바꿔줬다면 아래 두 코드를 입력한다. 그럼 실행된 것이다.
start-dfs.cmd 혹은 start-dfsstart-yarn.cmd 혹은 start-yarn
그리고 폴더를 만들거나 새로운 데이터를 넣고 싶다면
cd .. 를 해 상위 폴더로 나온 뒤에 하면된다.
디렉터리랑 csv파일은 하나 넣어본 것이다ㅎㅎ 넣는 방법은 생략

* ( + 추가. 22.02.21)
혹시 위에 코드만으로 안되면 아래 이코드 먼저 실행하고 위에 코드 실행하기
아래 사진처럼 저 위치에서 해야함!!
hadoop-env
*
종료하고 싶을 때는 다시 sbin 파일로 들어가 stop-dfs 와 stop-yarn을 해주면된다.
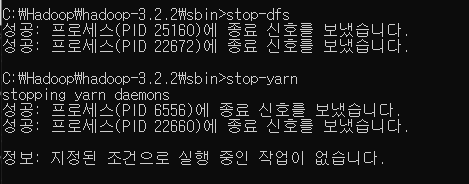
보통 가상환경 위에 리눅스에 많이 설치하는데
윈도우에서 하는 방법도 있길래 해봤는데 정말 머리가 깨질 뻔 했다 : )
'Big Data' 카테고리의 다른 글
| [Hadoop] 디렉터리 생성 & 파일 올리기 (0) | 2022.03.11 |
|---|---|
| [Spark] pyspark로 hdfs 데이터 불러오기 (0) | 2022.02.24 |
| [Spark] 스파크의 기본 개념 (0) | 2022.02.17 |
| [Spark] pyspark 설치 & 실행하기 (0) | 2022.02.15 |
| [Hadoop] 하둡의 기본 개념 (0) | 2022.02.14 |



