
Just Fighting
LSTM을 이용한 텍스트 생성 연습(2) - 모델 생성 본문
이전 글 ▼
2022.06.01 - [ETC] - LSTM을 이용한 텍스트 생성 연습(1) - 데이터 전처리
모델을 만들기에 앞서 먼저 단어 집합을 만들어주었다.
모든 문장들에 있는 단어들을 Tokenizer를 이용해 번호를 붙여준다.
# 단어집합 만들기
tokenizer = Tokenizer()
tokenizer.fit_on_texts(preprocessed_headline)
그리고 단어집합의 크기를 구한다.
단어 집합의 크기는 3493개였으나, 예제에서 1을 더해서 3494개라고 했다.
그 이유는 위에 사진에서 번호가 1부터 매겨져 있기 때문에
인덱싱을 위해서 1을 더해준다고 한다.
실제로 1을 더하지 않고 모델링에 넣어주었더니 오류가 났었다.
vocab_size = len(tokenizer.word_index)+1
vocab_size
다음으로는 정수 인코딩을 해준다.
texts_to_sequences()를 이용해 문장을 단어 단위로 나누어 위의 단어 집합에 있는 번호를 매긴다.
그리고나서 두 어절부터 하나씩 추가하며 새로운 리스트에 넣어준다.
예를 들어, '나는 오늘 저녁에 밥을 먹었다'를
['나는', '오늘'], ['나는', '오늘', '저녁에'], ['나는', '오늘', '저녁에', '밥을'], ['나는', '오늘', '저녁에', '밥을', '먹었다']
와 같이 만들어주는 것이다.
그렇다면 아래 사진과 같은 결과를 얻을 수 있다.
# 정수 인코딩
sequences = list()
for sentence in preprocessed_headline:
encoded = tokenizer.texts_to_sequences([sentence])[0]
for i in range(1, len(encoded)):
sequence = encoded[:i+1]
sequences.append(sequence)
texts_to_sequences() 함수의 결과를 확인해보기 위해 돌려본 코드의 결과이다.

그 다음으로는 패딩을 해주어야 한다.
모든 샘플들을 같은 길이로 만들어주기 위해서
가장 긴 샘플의 길이를 구하고 그 만큼의 길이로 모든 데이터를 패딩해주는 과정을 거친다.
pad_sequences()의 매개변수인 padding은 'pre'와 'post'가 있는데
'pre'는 앞을 0으로 채우고, 'post'는 뒤를 0으로 채운다.
또한 매개변수인 value를 이용해 0대신에 다른 수로 채울 수도 있다고 한다.(디폴트가 0)
# 샘플의 최대길이 구하기(패딩을 위해서)
max_len = max(len(i) for i in sequences)# 최대 길이인 24로 패딩하기
# pre는 앞에를 채우는 것
sequences = pad_sequences(sequences, maxlen = max_len, padding='pre')

-------------------------------------------------- * 추가 2023/01/03
패딩할 때 0을 앞에 채워주는 것이 좋다고 함 !
이유는 학습할수록 앞의 내용을 잊기 때문.
그리고 x와 y를 분리해준다.
# 정답 분리하기 (맨 우측 단어만 분리)
sequences = np.array(sequences)
X = sequences[:,:-1]
y = sequences[:,-1]
--------------------------------------------------
그리고 다음으로는 원 핫 인코딩을 진행한다.
y가 명목형이기 때문에 원 핫 인코딩을 해주어야 한다.
# y에 대한 원핫인코딩
y = to_categorical(y, num_classes=vocab_size)
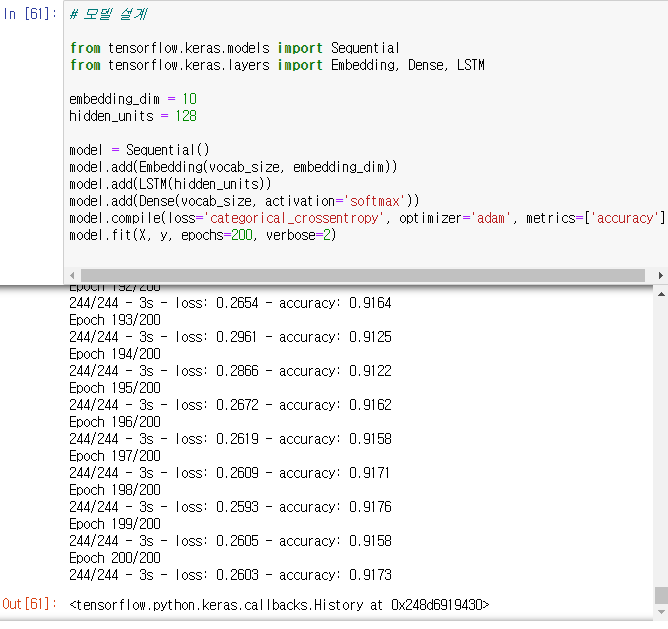
마지막으로 모델을 설계만 하면 된다.
임베딩 차원은 10, 은닉층의 크기는 128로 하고 LSTM의 모델을 만든다.
마지막에는 3494(vocab_size)개의 단어 중에 하나가 결과로 나오게 된다.
활성화 함수는 소프트맥스, 손실함수는 크로스 엔트로피, 최적화 알고리즘은 adam을 사용하여 200 에포크를 수행한다.
그리고 훈련을 모니터링 하기위한 지표는 accuracy를 사용한다.
(참고 : https://wooono.tistory.com/100)
# 모델 설계
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Dense, LSTM
embedding_dim = 10
hidden_units = 128
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(LSTM(hidden_units))
model.add(Dense(vocab_size, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X, y, epochs=200, verbose=2)
모델을 사용해보기 위해 예제의 함수를 이용해보았다.
새로운 단어를 앞선 과정과 똑같이 숫자로 바꿔주고, 패딩하는 과정을 거쳐
모델에 넣고 돌린 뒤에 결과를 얻는다.
그리고 그 나온 결과를 합쳐 또 다시 모델을 돌리고 그 과정을 반복하면
아래 두 개의 결과와 같이 나오게 된다.

역시 이것도 결과가 내맘 같진 않다^^;;;ㅋㅋㅋㅋㅋㅋㅋㅋ
'ML & DL' 카테고리의 다른 글
| [PySpark] 나이브 베이즈 실습 (0) | 2022.06.09 |
|---|---|
| [개념 정리] 나이브 베이즈 (Naive Bayes) (0) | 2022.06.08 |
| LSTM을 이용한 텍스트 생성 연습(1) - 데이터 전처리 (0) | 2022.06.01 |
| [개념 정리] 의사 결정 나무 (0) | 2022.05.03 |
| RNN을 이용한 텍스트 생성 연습 (0) | 2022.04.07 |



